title = "ReflectSumm: A Benchmark for Course Reflection Summarization",
author = "Zhong, Yang and Elaraby, Mohamed and Litman, Diane and Butt, Ahmed
Ashraf and Menekse, Muhsin",
editor = "Calzolari, Nicoletta and Kan, Min-Yen and Hoste, Veronique and
Lenci, Alessandro and Sakti, Sakriani and Xue, Nianwen",
booktitle = "Proceedings of the 2024 Joint International Conference on
Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)",
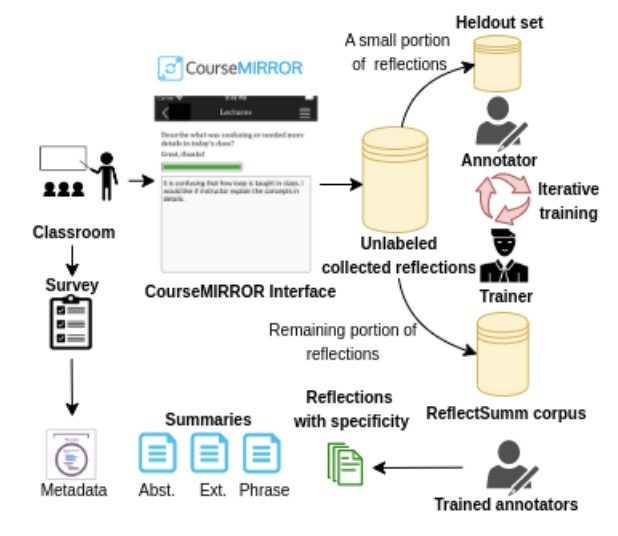
abstract = "This paper introduces ReflectSumm, a novel summarization dataset
specifically designed for summarizing students' reflective writing. The goal of ReflectSumm is
to facilitate developing and evaluating novel summarization techniques tailored to real-world
scenarios with little training data, with potential implications in the opinion summarization
domain in general and the educational domain in particular. The dataset encompasses a diverse
range of summarization tasks and includes comprehensive metadata, enabling the exploration of
various research questions and supporting different applications. To showcase its utility, we
conducted extensive evaluations using multiple state-of-the-art baselines. The results provide
benchmarks for facilitating further research in this area.",
abstract = "This paper presents an overview of the ImageArg shared task, the
first multimodal Argument Mining shared task co-located with the 10th Workshop on Argument
Mining at EMNLP 2023. The shared task comprises two classification subtasks - (1) Subtask-A:
Argument Stance Classification; (2) Subtask-B: Image Persuasiveness Classification. The former
determines the stance of a tweet containing an image and a piece of text toward a
controversial topic (e.g., gun control and abortion). The latter determines whether the image
makes the tweet text more persuasive. The shared task received 31 submissions for Subtask-A
and 21 submissions for Subtask-B from 9 different teams across 6 countries. The top submission
in Subtask-A achieved an F1-score of 0.8647 while the best submission in Subtask-B achieved an
F1-score of 0.5561.",
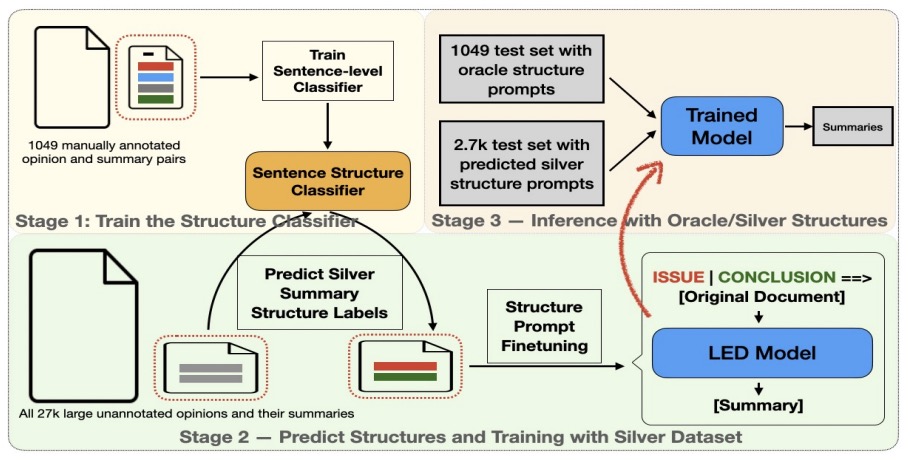
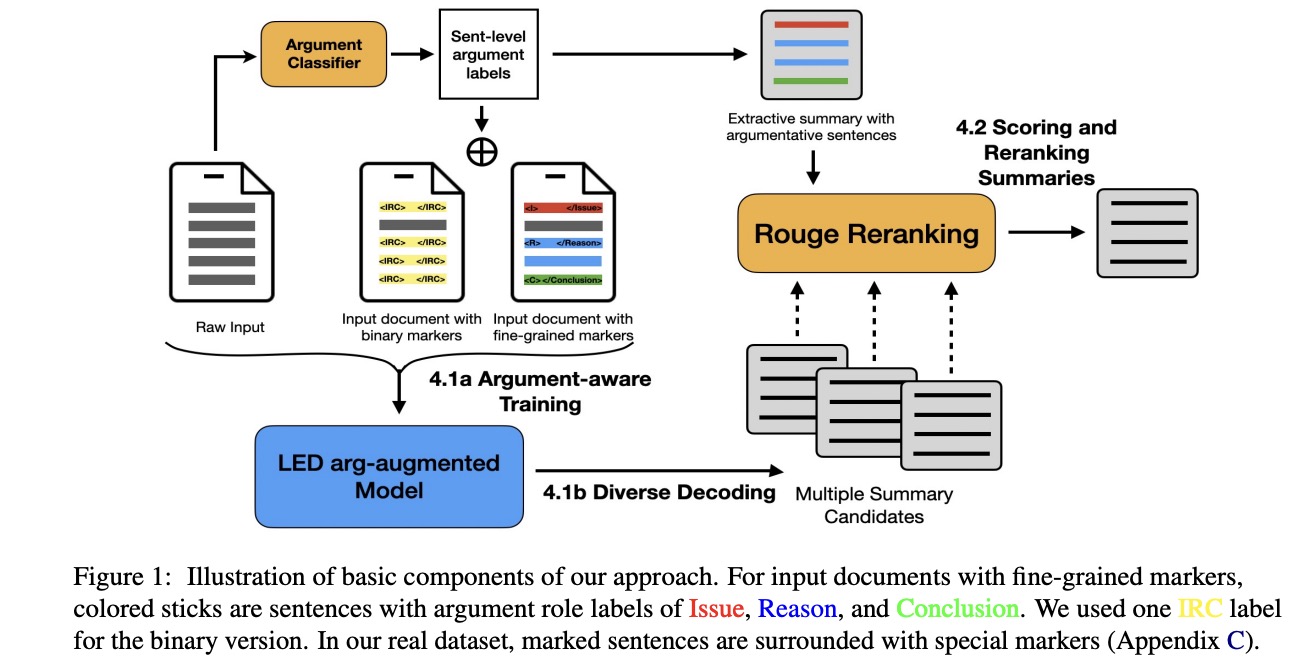
abstract = "We propose a simple approach for the abstractive summarization
of
long legal opinions that takes into account the argument structure of the document. Legal
opinions often contain complex and nuanced argumentation, making it challenging to generate a
concise summary that accurately captures the main points of the legal opinion. Our approach
involves using argument role information to generate multiple candidate summaries, then
reranking these candidates based on alignment with the document{'}s argument structure. We
demonstrate the effectiveness of our approach on a dataset of long legal opinions and show
that
it outperforms several strong baselines.",
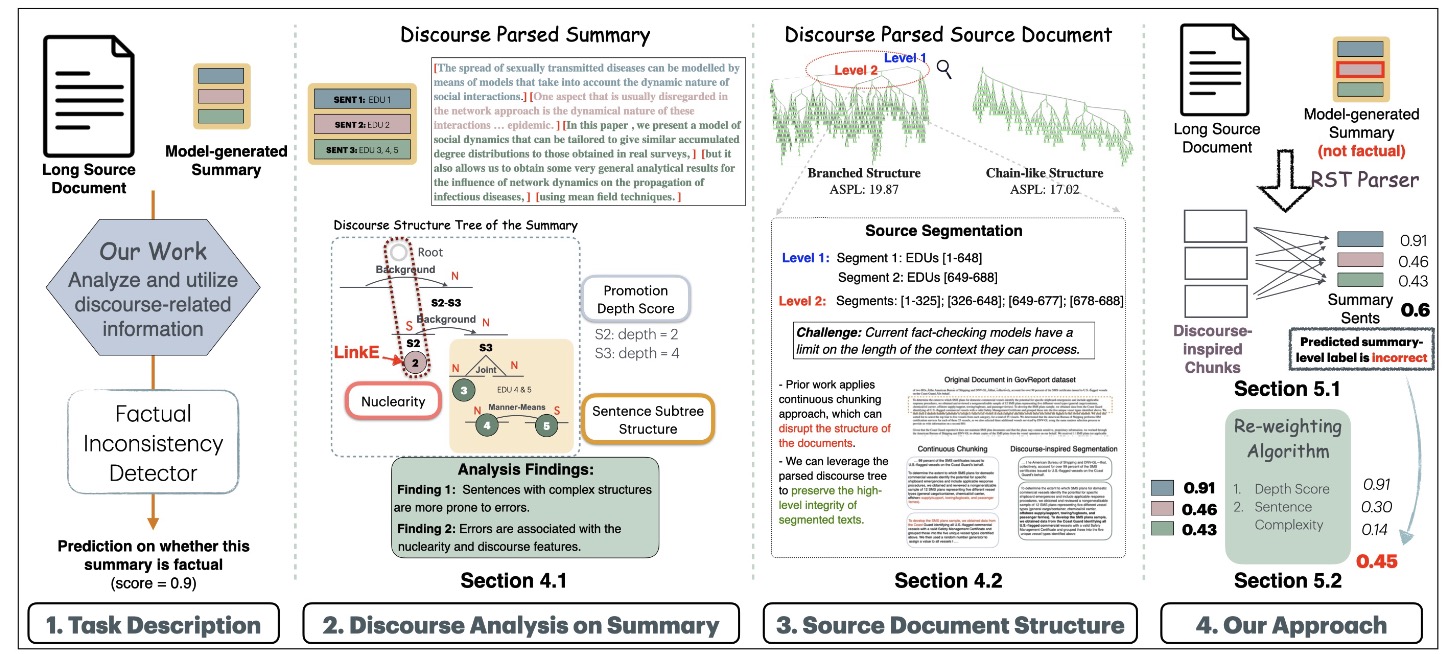
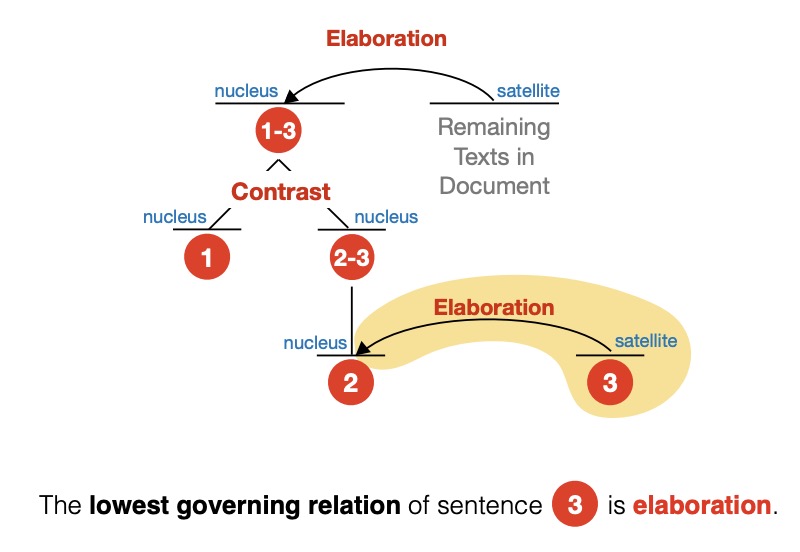
abstract = "Though many algorithms can be used to automatically summarize
legal case decisions, most fail to incorporate domain knowledge about how important sentences
in
a legal decision relate to a representation of its document structure. For example, analysis
of
a legal case sum- marization dataset demonstrates that sentences serving different types of
argumentative roles in the decision appear in different sections of the document. In this
work,
we propose an unsupervised graph-based ranking model that uses a reweighting algorithm to
exploit properties of the document structure of legal case decisions. We also explore the
impact
of using different methods to compute the document structure. Results on the Canadian Legal
Case
Law dataset show that our proposed method outperforms several strong baselines.",
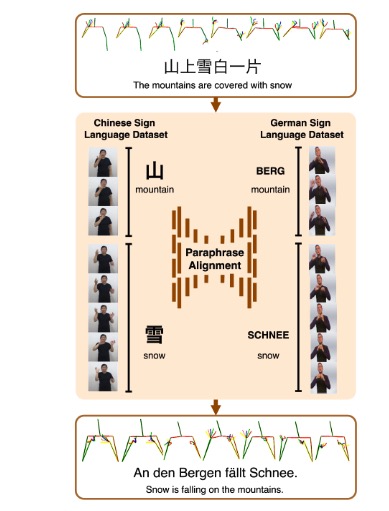
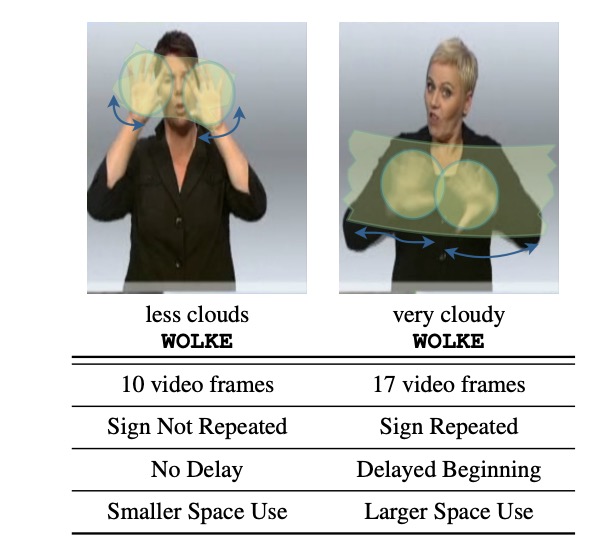
abstract = "End-to-end sign language generation models do not accurately
represent the prosody in sign language. A lack of temporal and spatial variations leads to
poor-quality generated presentations that confuse human interpreters. In this paper, we aim to
improve the prosody in generated sign languages by modeling intensification in a data-driven
manner. We present different strategies grounded in linguistics of sign language that inform
how
intensity modifiers can be represented in gloss annotations. To employ our strategies, we
first
annotate a subset of the benchmark PHOENIX-14T, a German Sign Language dataset, with different
levels of intensification. We then use a supervised intensity tagger to extend the annotated
dataset and obtain labels for the remaining portion of it. This enhanced dataset is then used
to
train state-of-the-art transformer models for sign language generation. We find that our
efforts
in intensification modeling yield better results when evaluated with automatic metrics. Human
evaluation also indicates a higher preference of the videos generated using our model.",
abstract = "Biases continue to be prevalent in modern text and media,
especially subjective bias {--} a special type of bias that introduces improper attitudes or
presents a statement with the presupposition of truth. To tackle the problem of detecting and
further mitigating subjective bias, we introduce a manually annotated parallel corpus WIKIBIAS
with more than 4,000 sentence pairs from Wikipedia edits. This corpus contains annotations
towards both sentence-level bias types and token-level biased segments. We present systematic
analyses of our dataset and results achieved by a set of state-of-the-art baselines in terms
of
three tasks: bias classification, tagging biased segments, and neutralizing biased text. We
find
that current models still struggle with detecting multi-span biases despite their reasonable
performances, suggesting that our dataset can serve as a useful research benchmark. We also
demonstrate that models trained on our dataset can generalize well to multiple domains such as
news and political speeches.",
abstract = "The success of a text simplification system heavily depends on
the
quality and quantity of complex-simple sentence pairs in the training corpus, which are
extracted by aligning sentences between parallel articles. To evaluate and improve sentence
alignment quality, we create two manually annotated sentence-aligned datasets from two
commonly
used text simplification corpora, Newsela and Wikipedia. We propose a novel neural CRF
alignment
model which not only leverages the sequential nature of sentences in parallel documents but
also
utilizes a neural sentence pair model to capture semantic similarity. Experiments demonstrate
that our proposed approach outperforms all the previous work on monolingual sentence alignment
task by more than 5 points in F1. We apply our CRF aligner to construct two new text
simplification datasets, Newsela-Auto and Wiki-Auto, which are much larger and of better
quality
compared to the existing datasets. A Transformer-based seq2seq model trained on our datasets
establishes a new state-of-the-art for text simplification in both automatic and human
evaluation.",
abstractNote = "<p>This paper presents a data-driven study focusing on
analyzing and predicting sentence deletion — a prevalent but understudied phenomenon in
document
simplification — on a large English text simplification corpus. We inspect various document
and
discourse factors associated with sentence deletion, using a new manually annotated sentence
alignment corpus we collected. We reveal that professional editors utilize different
strategies
to meet readability standards of elementary and middle schools. To predict whether a sentence
will be deleted during simplification to a certain level, we harness automatically aligned
data
to train a classification model. Evaluated on our manually annotated data, our best models
reached F1 scores of 65.2 and 59.7 for this task at the levels of elementary and middle
school,
respectively. We find that discourse level factors contribute to the challenging task of
predicting sentence deletion for simplification.</p>",
number = "05",
journal = "Proceedings of the AAAI Conference on Artificial Intelligence",
author = "Zhong, Yang and Jiang, Chao and Xu, Wei and Li, Junyi Jessy",
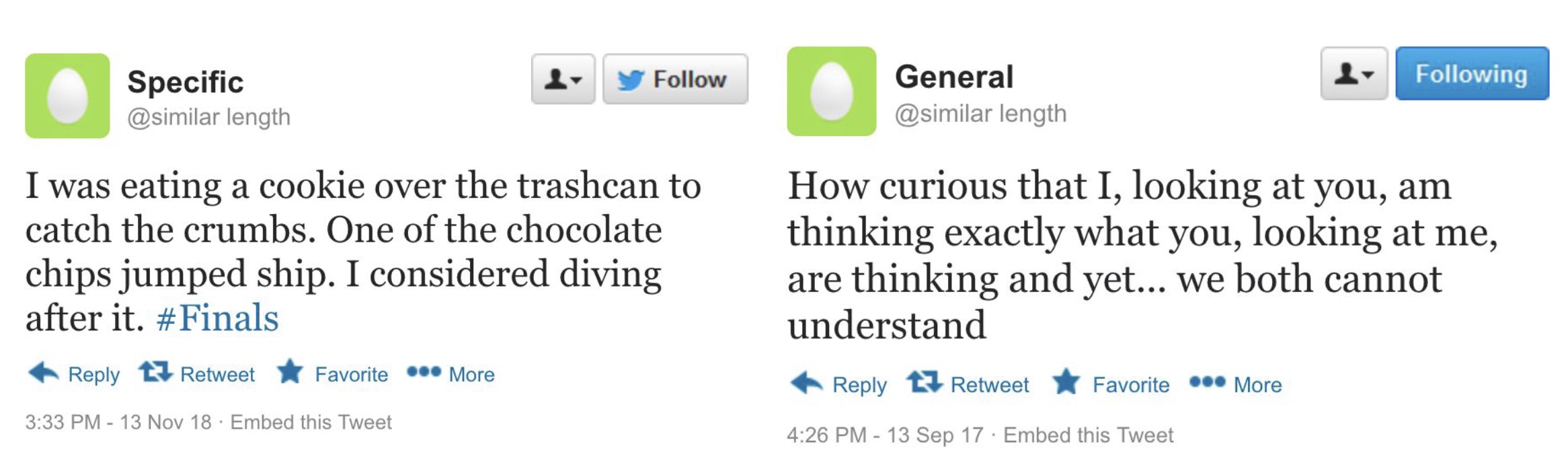
abstractNote = "<p>In computational linguistics, specificity
quantifies
how much detail is engaged in text. It is an important characteristic of speaker intention and
language style, and is useful in NLP applications such as summarization and argumentation
mining. Yet to date, expert-annotated data for sentence-level specificity are scarce and
confined to the news genre. In addition, systems that predict sentence specificity are
classifiers trained to produce binary labels (general or specific).</p><p>We
collect
a dataset of over 7,000 tweets annotated with specificity on a fine-grained scale. Using this
dataset, we train a supervised regression model that accurately estimates specificity in
social
media posts, reaching a mean absolute error of 0.3578 (for ratings on a scale of 1-5) and 0.73
Pearson correlation, significantly improving over baselines and previous sentence specificity
prediction systems. We also present the first large-scale study revealing the social, temporal
and mental health factors underlying language specificity on social media.</p>",
number = "01",
journal = "Proceedings of the AAAI Conference on Artificial Intelligence",
author = "Gao, Yifan and Zhong, Yang and Preoţiuc-Pietro, Daniel and Li,
Junyi
Jessy",
year = "2019",
month = "Jul.",
pages = "6415-6422"
}
Service
Reviewer: ACL ARR (2022-now), EMNLP 2023, ACL 2023, ACL 2022, AAAI 2021, AAAI 2020, Transactions on
Information Systems
Miscs
I am interested in photography, hiking,
travelling and cooking.